

This article addresses some of the terms used in the daily life of a developer in the field of computer vision. As it is an area that frequently meets demands from various fields, knowledge of some of these terms is essential for effective communication between the client and the developer. In this case, examples of situations will be presented, and some common methodologies when working with computer vision algorithms will also be discussed, preparing the ground for future articles in this area.
1. Detection vs Segmentation
A large part of computer vision algorithms aims to locate a specific object on the screen. This object localization can be performed in several different ways, and one of the differences is related to the number of points used in this localization.
Object detection generally involves the use of bounding boxes, which are rectangular boxes that delimit objects in the image. In detection, two main forms of coordinate organization are used. One is through two points in the form {(Xi, Yi), (Xf, Yf)}, where the indices i refer to the initial points and the indices f refer to the final points. Another way is to use {(Xi, Yi), (Xi + w, Yi + h)}, the difference being that instead of directly representing the final points, they are represented using the width (w) and height (h) of the box. Note that both representations are equivalent, as h = Yf - Yi and w = Xf - Xi.
An important observation here is that the point (0,0) is at the top-left corner of the image — most tools follow the OpenCV standard.
Below is an image to exemplify both forms of marking the image.
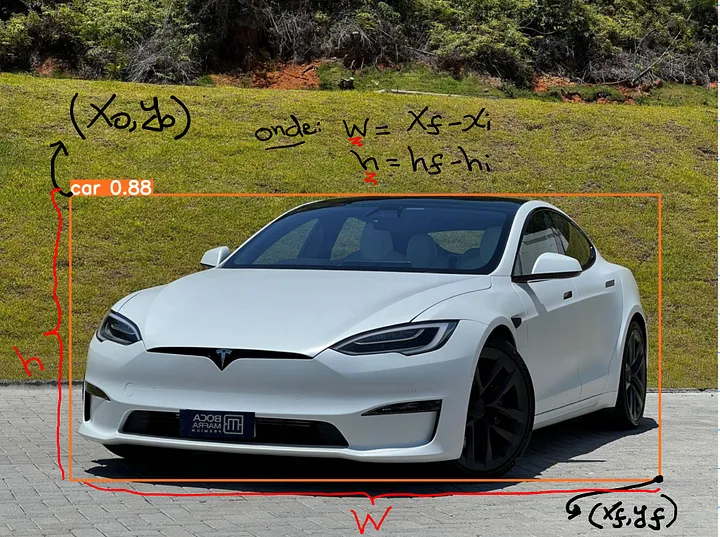 source: adapted from https://bocamafrapremium.com.br/wp-content/uploads/2024/01/a68adbb0011344528390c064df17a5e1_1671800981736.jpg
source: adapted from https://bocamafrapremium.com.br/wp-content/uploads/2024/01/a68adbb0011344528390c064df17a5e1_1671800981736.jpg
After understanding the use of the term detection, let's move on to the concept of segmentation. Imagine that, in addition to knowing the location of an object in the image, you would like to know a shape that closely approximates that object and how it behaves in space over time, for example. For this context, segmentation is necessary, which is a representation of the closest possible shape of the object using multiple points. In this case, there is no exact standard for representing the points.
Below is an example of how this form of representation is carried out (note the shape of the car highlighted within the bounding box).
 source: adapted from https://bocamafrapremium.com.br/wp-content/uploads/2024/01/a68adbb0011344528390c064df17a5e1_1671800981736.jpg
source: adapted from https://bocamafrapremium.com.br/wp-content/uploads/2024/01/a68adbb0011344528390c064df17a5e1_1671800981736.jpg
At this point, you might be wondering... but how would this look in terms of code? Since there are several detection tools, I will provide a generic example to illustrate in Python code:
import cv2
# assumindo que você tenha a representação dos seus quadros
for frame in frames:
# assumindo que 'detect' é uma função que retorna uma lista de detecções para um quadro
detections = detect(frame)
for detection in detections:
x0, y0, xf, yf = detection.xyxy
# Agora é só usar as coordenadas (x0, y0, xf, yf) para processar cada detecção
frame = frame[y0:yf,x0:xf]
2. Recognition
Another widely used term is recognition, which refers to the classification of a detected object into a specific type within a limited set. If you got confused by my definition, don't worry... Here are some examples: facial recognition, character recognition, scene recognition, gesture recognition, etc. In other words, these are scenarios where, in addition to detecting an object (associating it with a generic class), you also classify it into a more specific set.
An algorithm designed to detect faces, for example, is not capable of recognizing who the face belongs to, and this is what differentiates it from a recognition model — although the recognition model can also include a detection step in its workflow.
Below are some examples of facial recognition, character recognition, and gesture recognition:
 Example of facial landmark segmentation in a facial recognition process.
Example of facial landmark segmentation in a facial recognition process.
Source: https://www.uol.com.br/tilt/noticias/redacao/2022/04/08/europa-esta-criando-a-maior-rede-de-reconhecimento-facial-do-mundo-entenda.htm
 Example of optical character recognition (OCR). Source: https://andersonarchival.com/services/optical-character-recognition/
Example of optical character recognition (OCR). Source: https://andersonarchival.com/services/optical-character-recognition/
 Example of gesture recognition using a hand point segmentation library; there are many tools with this functionality, with Mediapipe being the most prominent currently. Source: https://developers.google.com/mediapipe/solutions/vision/gesture_recognizer
Example of gesture recognition using a hand point segmentation library; there are many tools with this functionality, with Mediapipe being the most prominent currently. Source: https://developers.google.com/mediapipe/solutions/vision/gesture_recognizer
3. Curiosity: Grayscale Images
Usually, an image is formed by a matrix with the dimensions of the image's width and height, in three different color scales. That is, a 512x512 pixel color image has a matrix of dimension 512x512x3. You may have already noticed the problem here, which is the use of memory to store these matrices.
In many computer vision applications, if you look at the code, you will see that on many occasions the images are converted to grayscale. This process is done when there is no interest in knowing the colors of the objects and you want to save memory, especially on edge devices that may have a very limited amount of RAM or integrated memory.
And here's another curiosity! Usually, images are represented using the RGB standard, which is the most common way to indicate the colors of objects. However, in one of the most famous image manipulation libraries, OpenCV, the standard is a little different, being BGR, which is the reverse of RGB. Therefore, be careful when manipulating your images, as OpenCV itself has a method for this which I will show below.
Here is an example of how to convert an image from BGR to RGB and how to convert an image to grayscale.
import cv2
# Carregar a imagem
imagem = cv2.imread('caminho_para_sua_imagem.jpg')
# Converter de BGR para RGB
imagem_rgb = cv2.cvtColor(imagem, cv2.COLOR_BGR2RGB)
import cv2
# Carregar a imagem
imagem = cv2.imread('caminho_para_sua_imagem.jpg')
# Converter para escala de cinza
imagem_cinza = cv2.cvtColor(imagem, cv2.COLOR_BGR2GRAY)
And that's it for today, folks! In the next article, I will cover the 10 most used functions in the daily life of a computer vision developer from the OpenCV library.